
新しくやり取りを始めたお客様が、初回のWeb会議で仰っておりました。
「データ活用する時に、前回組織名を繋げたり分解したりするのどうにかならないですかね?」
誰もが頷くであろう、この質問。
「繋げたり、分解したりはどうにもならないですよね。でも・・・」
という感じで答えさせていただきました。
人事だけではないと思いますが、データの作業や数字をいじる前に、「まずデータを少し整える」作業から始まることはとても多いです。
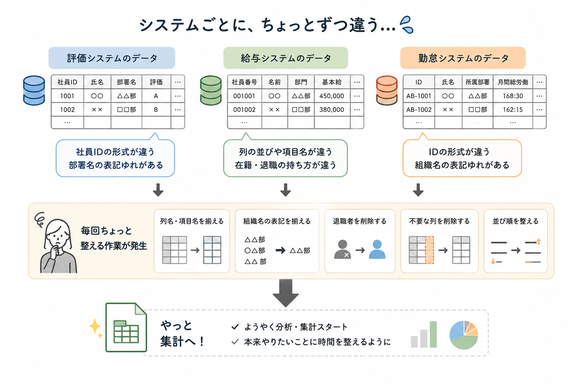
例えば、下記のような作業はよく発生しています。
- 退職者を除外する
- 組織名の表記を揃える
- 不要な列を削除する
- 並び順を整える
- 空白行を消す
- 社員番号の形式を合わせる
どれも小さな作業ですが、毎回となると結構地味にきいてきます。
特に人事DB・給与・勤怠・評価など複数データを扱うようになると、出力したCSV側で対応しないといけない場合がどうしてもあります。
- システムごとに列の並びや項目名が違う
- 在籍・退職の管理方法が違う
- 同じ組織でもカラムの持ち方や、できる表記が微妙に違う
これは、各システムは”業務”を適切に処理すること、が目的ですので、仕方がない部分でもあります。
(もちろんシステム自体を同シリーズに揃えられると、この辺りの作業はだいぶ楽になりますね)
最近は、当社へのご相談でも、「分析したい」「シミュレーションしたい」という話が増えていますが、
実際にはその前段の“整える作業”に多くの時間を使っているケースも少なくありません。
そこで、月次データ支援で、私たちが工夫しているのは、”整える作業”の改善ではなく、”毎回”の部分です。
”毎回”よく使う形式を少しずつ整理しておく、ことで、即データ活用(集計、分析、シミュレーションなど)に入れるからです。
当社ではこれを、「人事コモンデータ」と名付けて、色々と工夫しています。
もちろん、Excelの加工技術が高い人を担当にする(教育する)などで”整える作業”自体を軽くすることはできます。
でも、限度はありますし、属人化してしまうという違う問題にもつながってしまいがちです。
一方で、”毎回”の部分は、「仕組み化」なので、再現性のある改善として、人事組織ではとても有効です。
活用するかわからないデータをコツコツ作成しておくのは大変ではありますが、月別の比較や年間集計・分析をする場合などは、もの凄い効いてきます。
人事データを頻繁に活用する企業の担当の方にはお勧めです。
人事データ相談デスクについては、こちらのページでご紹介しています。
